Abstract
In robot manipulation, robot learning is becoming a prevailing approach. However, generative models
within this field face a fundamental trade-off between the slow, iterative sampling of diffusion models
and the architectural constraints of faster Flow-based methods, which often rely on explicit consistency
losses.
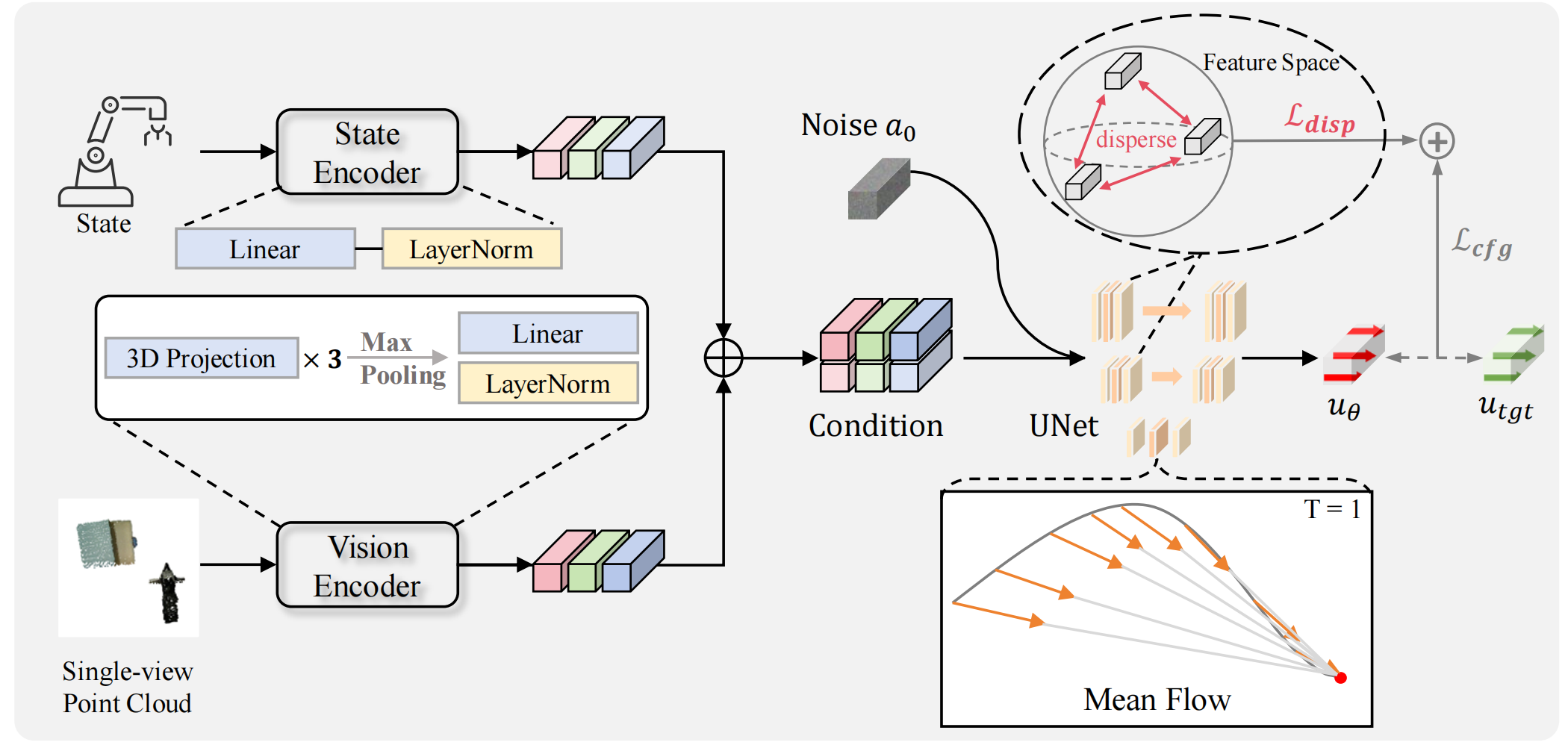
To address these limitations, we introduce MP1, which pairs 3D point-cloud inputs with the MeanFlow
paradigm to generate action trajectories in one network function evaluation (1-NFE). By directly
learning the interval-averaged velocity via the MeanFlow Identity, our policy avoids any additional
consistency constraints. This formulation eliminates numerical ODE-solver errors during inference,
yielding more precise trajectories.
MP1 further incorporates CFG for improved trajectory controllability while retaining 1-NFE inference
without reintroducing structural constraints. Because subtle scene-context variations are critical for
robot learning, especially in few-shot learning, we introduce a lightweight Dispersive Loss that
repels state embeddings during training, boosting generalization without slowing inference.
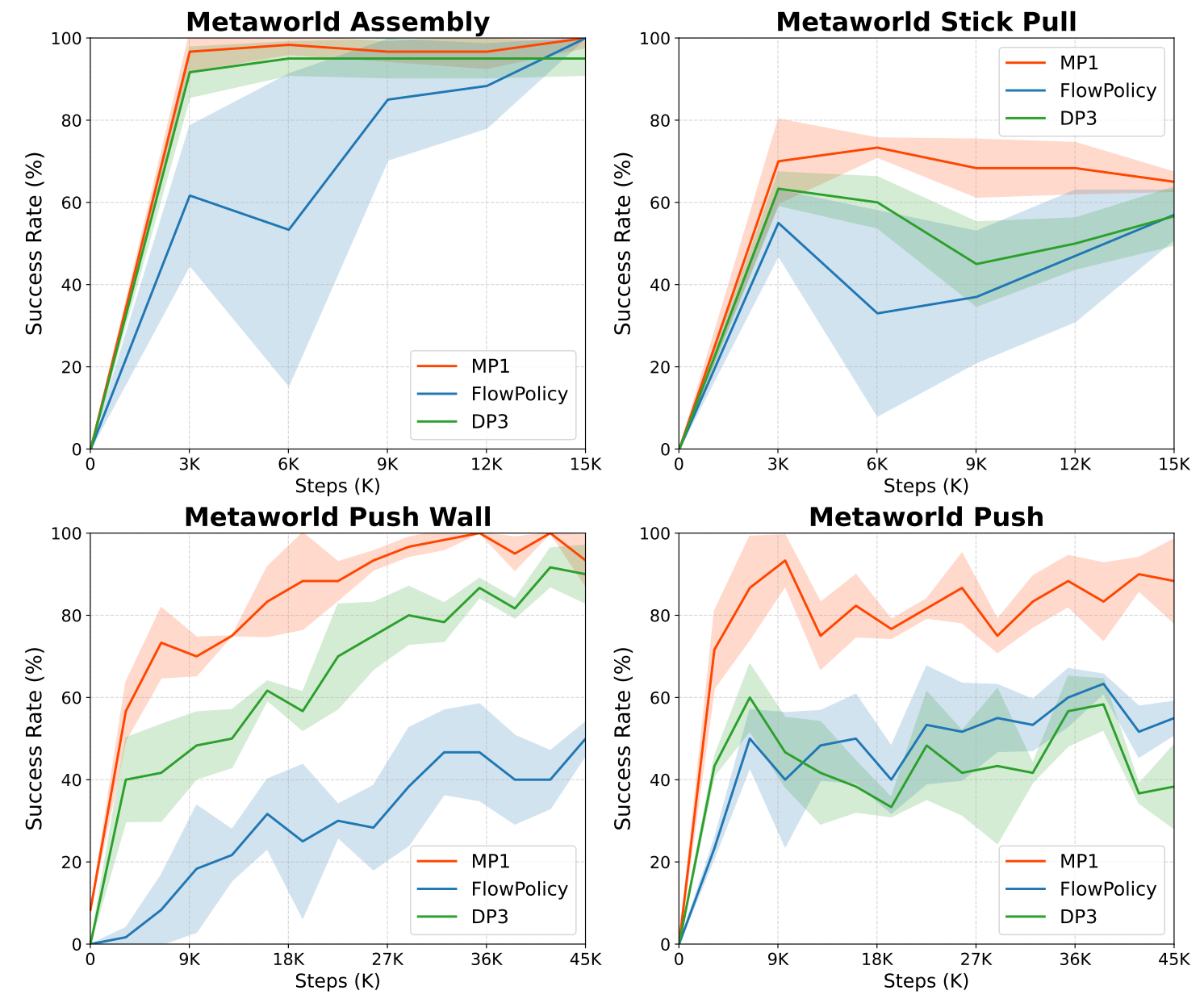
We validate our method on the Adroit and Meta-World benchmarks, as well as in real-world scenarios.
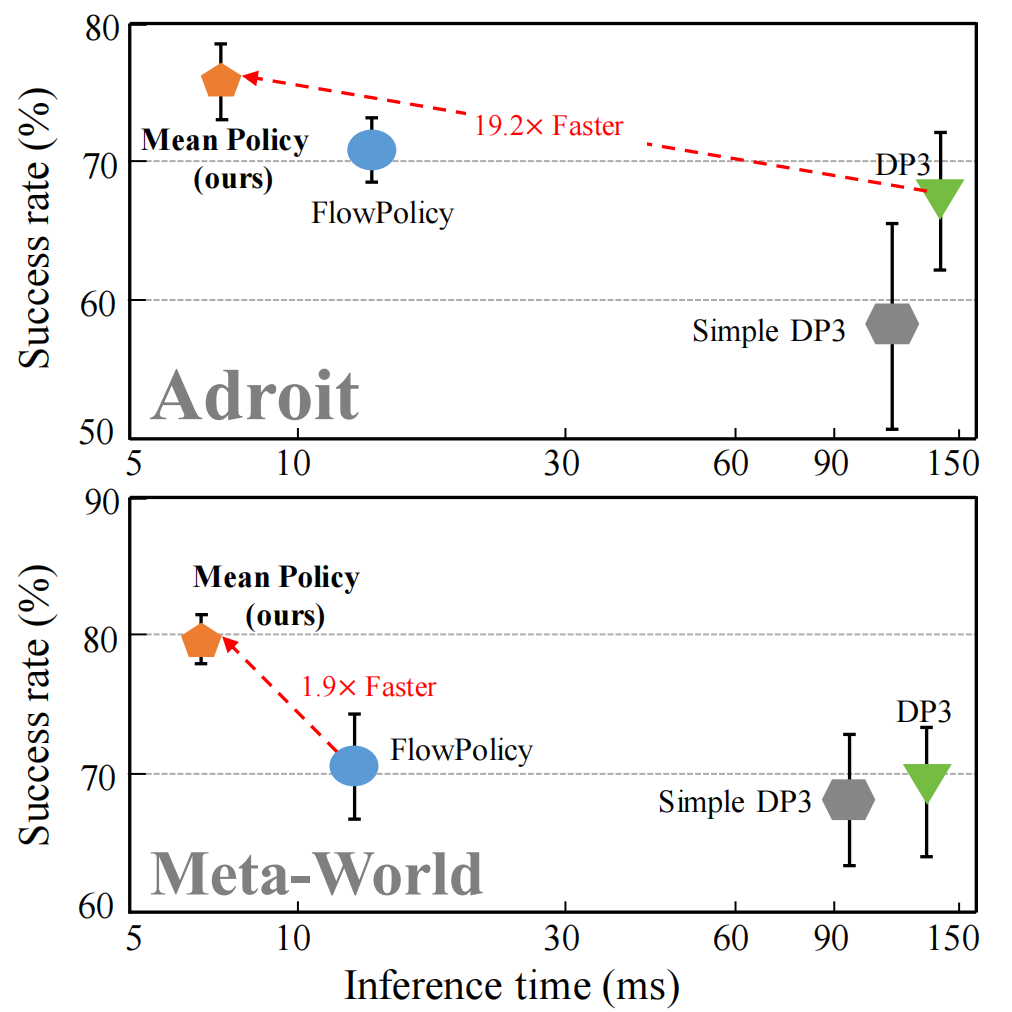
Experimental results show MP1 achieves superior average task success rates, outperforming DP3 by 10.2%
and FlowPolicy by 7.3%. Its average inference time is only 6.8 ms—19× faster than DP3 and nearly 2×
faster than FlowPolicy.
Our code is available at https://github.com/LogSSim/MP1.